Arma模型流程图
系统的定义。应用程序中的主要挑战的过滤器来预测降水和流速及流水量定义适当的矩阵和其他组件的过滤器的hydrologie变量和估计他们从可用数据和知识的物理过程。在随后的章节中各种统计技术的应用,包括卡尔曼滤波器预测hydroclimatic过程,特别是降水和河川径流,。
3随机降水预报
降水预报具有重要意义的水资源管理和防洪,尽管它不是一项容易的任务。降雨量的预测分析的基础上的时间和空间演化气象现象就总是可取的。在这方面已取得相当大的进展通过使用数值天气预报方法和环流模型。然而,这些来源的信息并不总是可用的操作形式。在这种情况下降雨预测可以基于当前和过去的持久性特征降雨量测量,即使这样的预测的准确性会受到影响,因为缺乏物理方面参与了沉淀现象。许多例子的降水预报统计,随机或概率技术可以在文献中找到。它们包括回归技术,马尔可夫链,ARMA-type方法,probability-function-based方法和人工神经网络(ann)。所有这些方法已被用于短期和中期长期预测,如下图所示。
短期预测
定量降水预报,通常表示为QPF,是洪水预报的主要任务之一。已经证明QPF允许延长交货时间的洪水预报的准确性,提高洪水估计对于一个给定的预测提前期(Brath et al ., 1988)。虽然在数值天气预报领域的研究近年来取得了重大进展(见,例如,Bougeault et al ., 2000),基于随机的预测技术和统计建模是特别有用的操作目的和中尺度流域的环境中,它的特点是快速响应时间。然而,由于降雨现象的复杂性,表现出明显的时空变异性,非平稳、非线性,尤其是在小尺度上,降雨量预测的随机方法涉及到一个具有挑战性的专长和经验。
早期的尝试预测降雨被制定为统计黑箱模型用于风暴跟踪。例如,Phanartzis(1979)开发了一个简单的模型来预测风暴的方向运动基于互相关雨量规的降雨测量在网络。类似的方法被开发
阮et al。(1978)使用雷达风暴跟踪信号。更复杂的风暴跟踪统计程序基于卡尔曼滤波器提出了约翰逊和胸罩(1980)。同时,法国和尼夫(1994年)和法国et al .(1994)使用卡尔曼滤波器的状态更新和公司的不确定性在基于二维物理模型和表面气象观测。此外,杉本et al .(2001)也使用扩展卡尔曼滤波器的状态估计量来更新模型参数的概念模型与新的雷达数据和预测的数值天气预报模式。
其他作者,如Lardet和obl(1994),生成场景降雨持续时间和体积的概率函数条件在过去降雨。统计方法基于分类树也被用于QPF(卡特和艾斯纳,1997;卡特et al ., 2000)。在其他应用程序中基于物理模型结构是结合随机组件占与模型假设和结构相关的不确定性(Jinno et al ., 1993)。河村建夫et al .(1996、1997)添加了一个高斯白噪声在时间和空间运动的对流模型的时空降雨,考虑一定程度的降雨中固有误差和不确定性建模。
其他方法努力克服的内在局限性persistence-based方法预测降雨,由于解相关时间短的降水过程订单的,这已被证明是大约20分钟(泽瓦茨基,1987)。基于四个随机方法预测短期降水呈现如下。
点过程模型。基于点过程模型执行令人满意地对集群复制依赖属性的实际降雨量(Entekhabi et al ., 1989)和相关的极端属性(Burlando罗索,1993)。然而,实时预测所需的配方是非常复杂的。拉米雷斯和胸罩(1985)开发了一个算法预测风暴到达假设Neyman-Scott白噪音模型作为底层rainfall-generating机制。他们得到时间的分布函数的一般表达式到下一个风暴事件,立即降雨的一部分历史条件,并应用该算法用于灌溉调度。法国et al。(1992)开发了一种实时预报方案基于Rodriguez-Iturbe的时空模型和Eagleson (1987)。预测模型由一个单一的分布式状态空间方程,用于推导的条件均值和条件方差的降雨强度。实时更新的降水场是由代表作为一个分布参数卡尔曼滤波模型结构。虽然做了一些工作在使用点和集群实时预报降水过程,其发展一直局限于研究。
回归方法。一个很好的例子有降雨基于统计方法的预测有用的操作目的是美国国家气象局的集中统计定量降水预报(Antolik, 2000)。统计预测是基于多元线性回归(德格拉恩和
洛瑞,1972;洛瑞和德格拉恩1976),降雨量在给定时间间隔预测气象变量的函数,观察和计算数值天气模型。尽管模型的相对简单,但往往优于物理方法和更复杂的技术为基础,根据预测的正确识别。回归方法的使用是更常见的长期预测。
马尔可夫链的方法。马尔可夫链的理论提出了短期和长期预测降雨。例如,据et al。(1992)使用一阶马尔可夫链的实时预测降雨几个小时时间,进而用于洪水预报。历史降雨数据分类在州的降雨变化范围划分为不重叠的时间间隔序列。过渡概率估计是j = (i, j - 1,…, r), r是州的数量,和钻井平台转换的状态我到j的数量,这是计算从历史观测在季节性的基础上。py值元素的转移概率矩阵,然后用来估计(预测)m-step(提前)跃迁概率的基础上传入的观察(例如,目前的状态)和给定条件nonexceedence概率。选择一个适当的nonexceeding概率是实现可接受的降雨预报的关键。Yu和阳(1997)采用了类似的方法,进一步分析所扮演的角色的选择nonexceeding概率预测的准确性。除了季节性依赖,nonexceeding概率很大程度上取决于风暴剖面,提高肢体的大大不同雨量计的衰退边缘。
Dahale和Puranik(2000) 6个州简单应用马尔可夫链预测空间降雨持续5天夏季季风在印度地区。Frae-drich和穆勒(1983)使用一个五状态简单的马尔可夫链,米勒和莱斯利(1984)采用了四个州的二阶模型来预测降雨概率从过去的天气状态。必须注意,高预测技能通常获得短的交货期,并显著减少与增加交货期。约翰逊和胸罩(1980)意味着降雨率的综合预测建模的整个事件在每个计随机剩余组件基于马尔可夫链的模型。选择最优的阶马尔可夫链中也扮演了重要的角色在预测精度。Akaike信息标准和贝叶斯信息准则可以用于此目的(例如,通,1975;Katz, 1981;格里高利et al ., 1992)。
ARMA模型。Trotta et al。(1977),和她们et al。(1981)表明,ARMA和传递函数模型可以用于建模降雨持久性。他们使用一个自回归传递函数模型对短期降雨预报的目的提高排污系统的控制。从历史数据模型使用参数估计风暴事件的开始,当信息的事件仍然是穷人。随着风暴的发展,逐步调整参数以反映增加实时信息。这样做是在一步包括权重因素的最小二乘估计算法为历史信息和当前帐户不同降雨事件信息。Obeysekera et al。(1987)表明,某些点过程模型广泛应用于建模短期降雨,如泊松矩形脉冲(PRP)和斯科特Neyman矩形脉冲(NSRP),拥有相关结构类似的ARMA(1,1)和ARMA(2, 2)模型,分别。因此,原则上,ARMA模型可用于模拟和预测短期降雨过程。因为ARMA模型是静止的,潜在的变量是正态分布,其应用程序实时短期降水预报,如每小时降雨量和日常需要遵循特定程序考虑这样的需求。Burlando et al。(1993)利用ARMA(2, 2)模型作为j =我=我Zt型= Xt - ju, Xt代表每小时降雨量,¡x是Xt的均值,4 > j和橙汁是自回归和移动平均系数,分别和e,是一个正态分布噪声平均值为零,方差一个\。
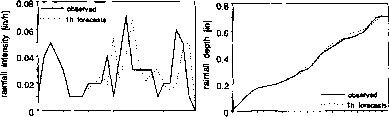
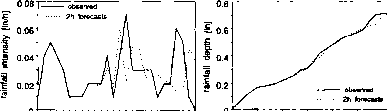
非平稳占全年降雨量的通过季节性估计参数分析的基础上进行连续数据集或基于事件的参数估计只有在提取非零降雨事件。后一种方法的一组不同的参数确定每个风暴事件。占的非线性特征风暴降水事件,一些修改是必要的估计ARMA模型(5)示意图如图1所示。具体来说,数据首先被转化为占non-normality通过Box-Cox转换(轮流地,1964),和模型参数的估计是由迭代自适应最小二乘技术。因此,可用的数据用于估计只有那些通过时间随着风暴事件的发展,隐式假设当地的平稳性。而基于连续的数据集的结果不满意,基于事件的应用程序提供了令人满意的结果。图2显示了一个示例的预测精度。一个明显的问题,然而,是一小时相移磨灭的预测事件。托斯et al。(2000)获得类似的结果通过轻微修改过程引入了Burlando et al。(1993),在基于事件的参数估计的基础上进行了一个移动窗口固定长度的数据序列而非完整的事件。转换的数据也放松,因为预测基于ARMA模型的应用程序不需要的数据是高斯分布,即:ARMA模型提供最佳线性预测即使对于非高斯数据(Brockwell和戴维斯,1991)。
时间相移展出由单变量预测获得ARMA模型可以部分解释为风暴运动引起的误差。可以改善这种效应通过选择额外的数据在其他邻近站测量(例如,通过使用的降雨在车站之间的互相关
-
.")
- 图1基于事件的ARMA预测过程的流程图(从Burlando et al ., 1993)。
.")
兴趣,即。,车站发出预报时,这些在其他站)和减少错误与移相关联。使用一个多元整合的ARMA (MARIMA)预测方案(Montanari et al ., 1994;Burlando et al ., 1996)。Montanari et al。(1994)建议一个多元方案可以显著提高预测当雨量规用于预测
从一开始的事件[h]时间事件(h)的开始
从一开始的事件[h]时间事件(h)的开始
时间从一开始的事件[h]时间从一开始的事件(4)
图2的例子1 -和2 h降雨预测事件的10月14日,1960年,科罗拉多州丹佛市获得通过的ARMA(2, 2)过程(从Burlando et al ., 1993)。
时间从一开始的事件[h]时间从一开始的事件(4)
图2的例子1 -和2 h降雨预测事件的10月14日,1960年,科罗拉多州丹佛市获得通过的ARMA(2, 2)过程(从Burlando et al ., 1993)。
充分选择。Burlando et al。(1996)表明,拉格朗日时空相关性的估计风暴移动的风暴可能会用地图记录的气象雷达,提供方向和风暴的速度运动。风暴跟踪可以被应用到实际事件选择那些具有最高的拉格朗日互相关站观测降水,因此最适合应用与多变量模型。因此多元模型估计的参数只使用实际降雨量在当前所选站事件。
特别是MARIMA模型估计未来出现的时间序列的线性组合(a)过去出现的时间序列的基本时间序列和it-i.e地阐述。,(b)的自回归组件和一个随机的当前和过去的事件白噪音component-i.e。移动平均线组件。MARIMA模型可以表示为
p和q的分别自回归和移动平均线的顺序,Z = (I - B)射频X„X,降雨强度,我是单位矩阵,B是落后的运营商,d是模型的差分秩序,和e,是一个正态分布噪声项。Z (X,«维列向量(n =数量的系列)和<£> 0 n X n自回归和移动平均模型的参数矩阵。参数的数量(6)变成了大订单p和q增加。这是一个主要限制在分析温顺和参数估计,尤其在那些情况下有限数量的观察是可用的。因此,p和q的值,以及n系列的数量,应该选为相互冲突的需求之间的妥协的过程叙述和数学温顺。
Burlando et al。(1996)的适用性探讨MARIMA(1 1 0)模型对流域在意大利北部。参数估计进行了个人事件,如Burlando et al。(1993),和使用矩量法
©Q7 = M0 - M, Mq ! Mf (7 b)
M0和乔丹表示lag-0 lag-1协方差,分别。台对的识别进行了历史的互关联的基础上或从分析进行实时雷达地图。后者提供了基础的运动学特征分析风暴,所以允许识别的(第一个)站,位于(二)顺风预测。领导站作为一个参考站第二站选择在那些位于风暴的方向运动,从雷达识别地图。MARIMA(1 1 0)因此估计使用雨计数据选择站,观察到在每个车站和降雨量预测发行作为当前和过去的事件的函数观察到在车站本身和铅。满意的结果报道在Burlando et al。(1996)。
人工神经网络。上述的另一种替代方法随机预测技术是使用人工神经网络。这些本质上是数据处理系统,可以通过学习繁殖之间的关系——或多维数据集。一个人工神经网络(ANN)是由许多简单的非线性单元,模拟人类的神经元。这些收集输入从一个或多个源产生一个输出根据预定义的非线性函数。在某种意义上一个安是一种传递函数模型,似乎是适合解决降雨预报的问题。
使用网络的目的与天气有关的数量在1990年代早期开始。法国et al。(1992 b)开发了一种神经网络预测降雨强度字段在时间和空间中,生成的一个修改版本的随机降雨Rodriguez-Iturbe提出的仿真模型和Eagleson (1987)。网络的输入,隐藏层和输出层使用——训练
652随机预测的降水和流速及流水量过程
传播技术在常规网格域测试的能力安调查的角色隐藏节点的数量在其性能。模型技能测试基于不同数量的训练集和降雨字段生成的随机模型。实时和离线学习学习是另外测试。Kuligowksi和巴罗斯(1998)应用相结合的降水数据的雨量规和风力方向为目标位置预测降雨量和交货时间6小时。具体而言,降雨观察雨量规在一个半径为300公里的地区集中在目标位置,上层风三个无线电探空仪位置和风向数据从多个水平相结合构建训练集的安。
最近,陆et al .(2000)采用人工神经网络来预测短期降雨对城市排水,针对调查的时间和空间的影响短期降雨预报信息。人工神经网络的预测精度是评价不同配置的延迟订单的数量和空间输入基于历史降雨模式。他们得出的结论是,最准确的预测依赖于识别空间最优数量的输入,和较低的网络延迟产生更好的性能。一个有趣的应用程序网络最近托斯et al .(2000)所示,为一个真实的案例研究提供比较网络性能对实时预测基于ARMA模型和非参数加权技术。多层前馈网络体系结构对单层测试方案以确定最佳的网络配置,对于split-sample应用程序和自适应校准。作为一个希望,更好的表现得到split-sample应用程序,这使得使用更大的训练集,而自适应校准给短交货期更糟糕的结果。相比于其他预测技术ann略优越的整体性能的能力占时间降雨特征的非线性。Grecu和尼夫(2000)报道的另一个有趣的应用反向传播神经网络(摘要)降雨预报。在这种情况下,降雨量并没有直接建模的摘要,但这是用来模拟统计雷达定量降水预报过程的一个组成部分。
继续阅读:中期和长期预测
这篇文章有用吗?