微生物在山坡上对比高程细菌和植物多样性的模式
杰西卡·a·布莱恩特*克里斯汀•LAMANNA +海琳莫伦·安德鲁·j·KERKHOFF * *布莱恩•j•+§和杰西卡·l·绿色*
高程梯度多样性的研究可以追溯到生物地理学的基础。尽管高程的模式植物和动物多样性研究了几个世纪以来,这种模式并没有被报道为微生物和仍然知之甚少。在这里,为了评估高程多元化模式的普遍性,我们研究了土壤细菌和植物多样性沿海拔梯度。来洞察这些模式的力量结构,我们采取了多方面的方法将信息结构、多样性、和空间营业额的山地社区系统上下文。我们发现观察植物和细菌多样性的模式是完全不同的。而细菌分类学的丰富性和系统发育多样性单调下降从低到高海拔地区,植物是单峰的模式,在山腰上的丰富和系统发育多样性。在海拔细菌社区系统集群有一个趋势,包含分类单元密切相关。相比之下,植物群落没有表现出一个统一的系统结构在梯度:他们越来越overdis-persed随着高程增加,包含远亲类群。
*生态学和进化生物学中心俄勒冈大学,尤金,或97403;“生态学和进化生物学、亚利桑那大学图森市阿兹85721;^部门生物学和数学,凯尼恩学院甘比尔,哦,43022;圣达菲§圣达菲研究所纳米87501;和应用生物多样性,HCenter科学保护国际,22202年弗吉尼亚州阿灵顿
128 /杰西卡·a·布莱恩特et al。
最后,一个度量系统beta-diversity表明细菌血统并非随机分布,而是表现出显著的空间结构梯度,而植物血统没有表现出显著的系统发育的信号。量化的影响样本规模intertaxonomic比较仍然是一个挑战。然而,我们的研究表明,沿高程梯度构建微生物和macroorganism社区的力量是不同的。
大约250年前,卡尔·林奈(1781)记录如何不同的植物和动物群落特征的气候区域沿着山脉的斜坡。这样eleva-tional梯度具有戏剧性的变化在气候和生物营业额地理距离短。raybet雷竞技最新林奈和他的同时代人所观察到的模式发挥了基础性作用发展的生态和生物地理学(布里格斯和汉弗莱斯,2004)。研究个人类群和社区组成如何应对高程梯度导致搜索广义高程的模式生物多样性(布朗,2001;Lomolino, 2001;麦凯恩,2005)。这些研究已经证实,高程的模式在各种各样的分类群的多样性,包括树木、哺乳动物、鸟类、爬行动物、昆虫和两栖动物。总之,这项工作表明,分类单元一般展览单调递减或hump-shaped丰富模式高度(史蒂文斯,1992;Rahbek, 2005)。然而,尽管大量的提出假设来解释海拔模式的多样性,他们的原因仍然知之甚少。 Improved knowledge of elevation gradients is fundamental to advancing basic ecology and predicting the potential consequences of climate change. Species in montane regions are often cited as being very sensitive to the impacts of warming (McDonald and Brown, 1992; Parmesan, 2006; Thuiller, 2007).
尽管高程模式多样性的植物和动物已经很成熟,我们知之甚少如何微生物多样性在不同高程梯度。这是一个严重的差距在我们一般对生物多样性的理解,考虑到微生物丰富和多样化,在生态系统功能中发挥核心作用,可能是生态系统应对全球变暖的一个重要组成部分(Rillig et al ., 2002;曼森et al ., 2006;卡尼et al ., 2007)。高程微生物多样性研究考虑macroorganisms的经验模式和并行需要理解多样性提供了一个更加统一的框架模式在地球的主要环境梯度和预测生态系统对气候变化的反应。
传统高程多样性研究关注的物种丰富度模式,丰富和范围大小与高度变化。这些分析使用了一个命名方法通过关注物种的身份。然而,增加可用性的分子的发展史已经重新燃起了兴趣,用系统方法来研究力量,影响的模式(如生物多样性和生物地理学。Chave et al。(2007)]。因为许多物种特征通常是守恒的进化谱系中,人会期望一个积极的关系的两个物种的系统发育关系,衡量他们的整体生态相似性(系统发育利基保守主义)(哈维·佩格尔,1991)。因此,类群的系统发育关系程度的分析中找到和在社区应该提供洞察组织这些社区的生态和进化过程。
在这里,为了评估高程的普遍性多元化模式,这些模式的力量结构,我们量化植物和土壤细菌多样性模式沿着科罗拉多洛矶山脉的高程梯度。一个吝啬的假设是,如果对面的力量构建生物多样性梯度对于细菌和植物都是相同的,那么产生的分类和系统发育生物地理的模式将为两组相似。另外,如果生态和进化过程沿高程梯度两组之间的差异(例如,不同类群的分散能力,应对环境异质性、种间相互作用,或物种形成的利率),我们期望他们会表现为不同的模式的多样性。检验这些假设,我们采取了多方面的方法,研究多元化的背景下生态与进化模式。因此,除了建立约定的量化模式分类单元的丰富性和分类单元沿梯度(例如营业额。惠塔克(1960,1967),我们检查了几个生物多样性的措施纳入信息系统结构、系统发育多样性和系统发育营业额的植物和细菌的社区。
高程系统上下文的多样性
虽然抽样方法和分类用来量化植物多样性建立和标准化,微生物调查差异很大的方式描述多样性(艾森,2007)。我们确定的细菌群落组成土壤样本通过分析16 s核糖体DNA扩增区域菌进行,微生物生物多样性的最常用的指标。因为土壤中的细菌绝大多数是多样化的,我们选择了PCR引物,门Acidobacteria缩小我们的焦点小组。这群细菌是多样化的和无处不在的土壤(詹森,2006),认为生物地球化学循环中扮演着重要的角色(Eichorst et al ., 2007)。
130 /杰西卡·a·布莱恩特et al。
我们跟着intertaxonomic多样性分析的经典方法通过比较模式的物种丰富度和phylotype丰富的植物和细菌,分别沿梯度。我们也量化每个采样的系统发育多样性社区通过计算分支长度之和的发展史,连接所有物种在一个社区和根(信仰,1992 b)。系统发育多样性比简单的计数更具包容性的物种或类型,它量化的进化历史一群分类单元(Vane-Wright et al ., 1991)。保育生物学家感兴趣的是保护系统发育多样性,因为这是最大化的基础为未来进化的选择(信仰,1994;迈尔斯和小山,2001;Sechrest et al ., 2002;森林et al ., 2007)。系统发育多样性也被认为与“功能多样性,”意义派生的进化特征的数量在一个生物群落(信仰,1992 b)。
除了测量系统发育多样性,我们量化社会系统结构沿梯度通过使用两个常用指标:平均成对phylogeny-wide距离度量敏感模式(净亲缘指数新名词)和nearest-taxon-based测量敏感模式的“技巧”发展史(最近的分类单元指数(NTI)](韦伯et al ., 2002)。系统发育的程度related-ness量化这些指标提供了洞察司机的社区大会。假设系统生态位保守主义,系统聚类在一个地方集合与假设是一致的选择性过滤器(例如,环境条件)导致当地组合构成密切相关类群(韦伯et al ., 2002)。系统发育overdispersion,另一方面,可以解释为两种可能的生物相互作用:竞争(韦伯et al ., 2002)或便利(Lortie, 2007;Valiente-Banuet一直,2007)。在竞争中,越来越多的密切相关的物种竞争的假设更强烈。这导致竞争排斥,从而导致一个社区的远亲的物种。在便利的情况下,主持人物种假设创建隐居,允许远亲物种适应不同环境持续在一个地方集合。
除了考虑模式的多样性和phyloge-netic结构社区内沿海拔梯度(alpha-diversity),我们调查了社区景观(beta-diversity)成分的变化。生态学家们早就认识到beta-diversity了解山地生态系统的生物多样性是很重要的(Jaccard, 1912;惠塔克,1960;哈特et al ., 1999;Brehm et al ., 2003;中东和北非地区和Vazequez-Dominguez, 2005)。我们检查了beta-diversity成分相似,定义为部分类群之间共享两个样品(S0rensen指数)和系统相似,定义为两个样本之间的分支长度的比例共享。通过类比的,距离衰减的关系,描述了组成相似性下降两个社区随着地理距离(或等同于高程分离)他们之间(Soininen et al ., 2007),我们描述了降低系统随着距离的相似性(系统发育,距离衰减)。我们的目标在探索beta-diversity措施不仅是理解如果有相似成分的变化随着高程增加距离,如预期的那样沿着环境梯度,但量化的系统特性变化。
系统相似度反映了组合添加剂的影响:(i)血统,两个社区之间共享导致分类群共享,共享和(2)血统,但最终导致非共享的类群。可以测试两个群体之间的系统发育相似是否单独成分相似的结果,或者如果它也引起的非随机结构共享和非共享血统。(即一个重要系统,距离衰减模式。,一个不同于预期仅靠类群营业额;见材料和方法)反映重要的空间变异性在天堂景观组成。基于上述假设系统利基的保守主义,血统组成的变化应该对应于物种的变化特征。在这种模式下,一个重要的系统发育,距离衰减关系应该反映相关的生态特征的强大变异生物景观社区。
结果与讨论
而细菌从低到高海拔地区丰富单调下降,植物丰富了单峰模式与物种丰富度的峰值midelevations(图7.1)。这些对比多样性模式出现丰富值计算时分别为细菌和植物样品,也当每个各自组的样本汇集在一起在每一个高程带[协议后提出了维特克(1960)]。据我们所知,一个alti-tudinal丰富模式从未报道微生物。这里观察到的模式对微生物和植物是一致的,分别用经典的单调递减和hump-shaped模式观察到在大多数macroorganism组(史蒂文斯,1992;麦凯恩,2005;Rahbek, 2005)。一直认为,这两个对比丰富模式可能出现的结果不一致的抽样方法在不同的研究中,而不是一个潜在的生态机制(Lomolino, 2001;Rahbek, 2005)。通过实现一个平行样品设计的细菌和植物,我们控制了两个潜在的偏见:杂文集-
132 /杰西卡·a·布莱恩特et al。
132 /杰西卡·a·布莱恩特et al。
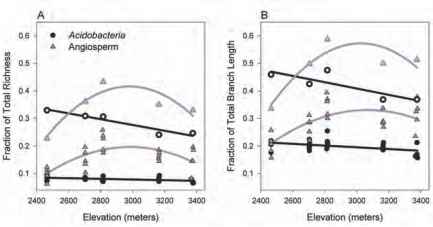
图7.1不同分类单元丰富(A)和(B)系统发育多样性海拔梯度。数据给出的分数总丰富和系统发育多样性梯度。固体符号表明样本丰富(核心或方形),和开放的符号显示各高程汇集丰富网站(n = 5 /网站)。在样本层面,Acidobacteria丰富性和系统发育多样性与海拔呈线性减少(回归分析,r2 = 0.22, P < 0.05;分别为r2 = 0.23, P < 0.05),而被子植物丰富度和系统发育多样性模式hump-shaped(回归分析,r2 = 0.53, P < 0.0005;分别为r2 = 0.47, P < 0.005)。模型的选择是基于Akaike信息标准。
图7.1不同分类单元丰富(A)和(B)系统发育多样性海拔梯度。数据给出的分数总丰富和系统发育多样性梯度。固体符号表明样本丰富(核心或方形),和开放的符号显示各高程汇集丰富网站(n = 5 /网站)。在样本层面,Acidobacteria丰富性和系统发育多样性与海拔呈线性减少(回归分析,r2 = 0.22, P < 0.05;分别为r2 = 0.23, P < 0.05),而被子植物丰富度和系统发育多样性模式hump-shaped(回归分析,r2 = 0.53, P < 0.0005;分别为r2 = 0.47, P < 0.005)。模型的选择是基于Akaike信息标准。
(即填写抽样程度。之间的地理距离最远的采样海拔),这常常发生在研究和抽样强度(或工作)中沿梯度分类组,这常常发生在研究。结果,差异之间的高程丰富模式观察细菌和植物很可能引起的生态和进化过程如何运作的差异在梯度(虽然见下文讨论缩放效果)的潜在影响。
正如所料,细菌和植物(森林et al ., 2007)我们发现的模式系统发育多样性反映分类单元的丰富性(图7.1 b)。然而,一个更详细的看看系统的细菌和植物群落结构显示另一个显著差异。在所有海拔细菌社区有一个倾向于比他们预想的更系统集群偶然(图7.2)。这个观察是一致的结果报道Horner-Devine和Bohannan(2006)发现,在广泛的环境中细菌社区往往是系统比预期更为密切相关
2400 2600 2800 3000 3200 3400 3600 2400 2600 3000年情况28日3200 MOO 3600
高度(米)高度(米)
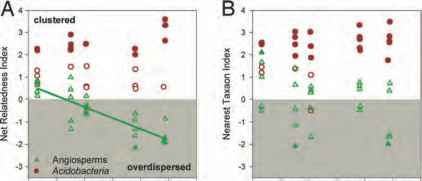
图7.2社区系谱亲缘沿海拔梯度的变化来衡量的新名词(A)和NTI (B)。积极的索引值指示系统聚类,和消极的价值观表示系统发育overdispersion。观察社会系统结构可能出现偶然(P < 0.05)是描述固体的象征。所有微生物群落聚集,> 50%是明显的集群。被子植物群落分布不均匀集群或梯度,而是越来越overdispersed与海拔的升高。这一趋势在增加overdispersion高程测量时重要的亲缘新名词(实线;r2 = 0.70, P < 0.001)。
2400 2600 2800 3000 3200 3400 3600 2400 2600 3000年情况28日3200 MOO 3600
高度(米)高度(米)
图7.2社区系谱亲缘沿海拔梯度的变化来衡量的新名词(A)和NTI (B)。积极的索引值指示系统聚类,和消极的价值观表示系统发育overdispersion。观察社会系统结构可能出现偶然(P < 0.05)是描述固体的象征。所有微生物群落聚集,> 50%是明显的集群。被子植物群落分布不均匀集群或梯度,而是越来越overdispersed与海拔的升高。这一趋势在增加overdispersion高程测量时重要的亲缘新名词(实线;r2 = 0.70, P < 0.001)。
偶然。考虑到吝啬的假设密切相关类群(即更生态相似。系统发育利基保守主义),我们的研究结果表明,非生物过滤往往是更重要的力量沿着梯度细菌社区的构建。几项研究表明,对大多数macroorganisms、生态特征是系统守恒(普林茨et al ., 2001;显得过于et al ., 2003;Cavender-Bares et al ., 2004)。重要的是要强调,尽管这种说法可能是正确的对于macrorganisms,利基保守主义的普遍性微生物特别是细菌是未知的。在微生物群落也可以观察系统聚类的结果辐射事件结合传播限制(Horner-Devine Bohannan, 2006)。我们在下面讨论,其他解释的模式我们观察与分析的系统发育和空间规模(斯文森et al ., 2006, 2007)。扩展问题相关的所有生物多样性模式我们检查了。
与细菌相比,植物群落没有一个统一的系统发育在梯度结构。植物群落往往
134 /杰西卡·a·布莱恩特et al。
表现出随机系统结构或系统发育overdispersion。令人惊讶的是,我们的分析表明,植物群落也倾向于变得越来越overdispersed在更高海拔(图7.2)。鉴于生态位保守主义,系统发育overdispersion符合生物力量的重要性(竞争排斥或便利)构建社区的多样性。最近的实验证据表明,这两种力量是重要的司机在高山植物群落组装,从竞争转变在海拔较低地区,条件不太身体压力,便利在高海拔地区非生物压力高(卡拉威et al ., 2002)。高海拔的增加overdispersion表明便利化海拔较高的社区的影响比在低海拔的影响。另一种解释是,进化的必要特质应对高海拔的环境条件在远亲血统(即独立发生。趋同进化,高高山植物)(韦伯et al ., 2002)。这个解释与系统发育利基保守主义的假设。
我们观察到植物和细菌组成相似性与高程距离显著降低(图7.3)。植物和细菌社区不同,然而,在他们的系统发育,距离衰减模式。细菌的系统发育,距离衰减曲线从观察到的细菌类群远比预期的营业额(图7.3)。相比之下,植物系统发育,距离衰减曲线没有明显不同于预期观察腐烂的植物成分相似。这些结果符合上述报道的新名词和NTI措施的社区系统结构,表明细菌血统并非随机分布在海拔梯度。相反,细菌血统展出梯度空间结构模式。考虑到吝啬的假设密切相关类群更生态(或功能)相似,我们的观察表明,细菌血统港口日益不同的生态功能(或功能)增加高程距离作为一个可能的非生物过滤的结果。这些发现强调收集信息的效用之间的系统发育关系山地地区的社区来量化的潜在后果有选择地修剪进化谱系的场景下山顶灭绝以应对全球变暖。
虽然我们的研究不是为了直接检查高程多样性的环境驱动模式,我们的结果照亮他们的潜在作用在塑造生物多样性梯度模式。对比我们观察到植物和微生物系统发育多样性模式显示不同的角色非生物力量如何跨梯度结构的社区。土壤温度和pH值考虑到,
成分相似系统零PCytogenetic相似。相似的操作系统1
成分相似系统零PCytogenetic相似。相似的操作系统1

0 200 < 00 600 BOO 100 d
改变高度(米)
图7.3 Acidobacteria社区的组成和系统相似度(A)和(B)被子植物社区,社区作为高度分离的函数。成分(空心黑色三角形)和系统(固体黑色圆圈)相似性对被子植物和Acidobacteria社区显著减少随着高程增加分离(壁炉架测试,P < 0.001)。行代表最佳回归的相似性和高程变化(见材料与方法)。衰变的斜率之间的系统发育相似Acidobacteria社区远比预测的一个空模型受到分类单元的减少营业额(固体灰色圆圈)(P < 0.05)。衰变的斜率在被子植物系统发育相似社区不是从零预测给定物种周转率明显不同。
0 200 < 00 600 BOO 100 d
改变高度(米)
图7.3 Acidobacteria社区的组成和系统相似度(A)和(B)被子植物社区,社区作为高度分离的函数。成分(空心黑色三角形)和系统(固体黑色圆圈)相似性对被子植物和Acidobacteria社区显著减少随着高程增加分离(壁炉架测试,P < 0.001)。行代表最佳回归的相似性和高程变化(见材料与方法)。衰变的斜率之间的系统发育相似Acidobacteria社区远比预测的一个空模型受到分类单元的减少营业额(固体灰色圆圈)(P < 0.05)。衰变的斜率在被子植物系统发育相似社区不是从零预测给定物种周转率明显不同。
帐篷与多样性的植物和细菌和细菌多样性也强烈边坡与单变量分析(表7.1)。多变量分析表明,土壤温度的主要解释变量分类单元丰富和系统发育多样性植物和细菌在6 8多变量模型(P < 0.001)。营业额在分类和系统发育明显与植物和细菌群落组成的变化大部分测量环境参数(7.2);然而,合并后的土壤的影响温度、pH值,总氮对两组是最重要的预测因子。在控制了这些环境参数、地理距离与所有营业额模式样本显著相关(部分壁炉架测试,P < 0.001)。这些结果暗示传播限制可能发生的,但考虑到梯度小的地理范围,他们更有可能引起的环境异质性的影响,我们没有描述。丰富的相关性和营业额与温度和pH值是一致的
多样性的类型 |
海拔高度 |
温度 |
pH值 |
坡 |
方面 |
氮 |
碳 |
水分 |
微生物丰富 |
-0.222 * |
0.174 * |
0.205 * |
-0.239 * |
0.044 |
-0.002 |
0.0002 |
-0.148 |
植物丰富 |
0.533 * * * |
-0.502 * * * |
-0.189 * |
0.004 |
0.039 |
0.271 |
0.077 |
0.045 |
微生物系统发育多样性 |
-0.228 * |
0.216 * |
0.132 |
-0.311 * |
0.030 |
-0.0001 |
0.116 |
-0.0009 |
植物系统发育多样性 |
0.473 * * |
-0.443 * * |
-0.283 * |
0.069 |
0.002 |
0.229 |
0.022 |
0.056 |
微生物的新名词 |
0.056 |
-0.063 |
-0.025 |
0.227 |
0.018 |
0.037 |
0.0001 |
0.002 |
植物的新名词 |
-0.696 * * * |
0.699 * * * |
0.536 * * * |
-0.411 * * |
0.132 |
0.094 |
0.056 |
0.001 |
微生物NTI |
0.101 |
-0.120 |
-0.054 |
0.048 |
-0.008 |
0.0004 |
-0.233 |
-0.026 |
植物NTI |
-0.109 |
0.109 |
-0.015 |
-0.015 |
0.002 |
-0.059 |
-0.037 |
-0.004 |
为每个环境参数线性和二次模型是合适的。选择最适合的模型使用最低Akaike信息准则(AIC)值(见材料与方法)。二次模型用斜体表示,减号(-)表示
* |
*有限公司 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
O |
O |
CN |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
O |
O |
O |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
O |
1 |
1 |
|

 are depicted with solid circles.")
